SEO技术:PageRank算法原理
-

-
小明 这家伙很懒,还没有设置简介...
0 人点赞了该文章 · 2 浏览
PageRank
长久以来,谷歌一直是全球最成功的互联网搜索引擎,但是现在的巨无霸并非第一个互联网搜索引擎。在谷歌之前,有很多通用或专门的搜索引擎。谷歌最终击败了所有竞争者,主要是因为它解决了困扰问题:根据重要程度给搜索结果排序。结束这问题的算法是PageRank。直言不讳地说,PageRank算法使得谷歌今天处于地位。要了解为何解决这个难题如此重要,就来看看搜索引擎的中心框架。
搜索引擎的核心架构
尽管搜索引擎已经发展多年,但其核心算法却没有多大变化。基本上,搜索引擎是一种数据检索系统。搜素爬虫机一般是收集网页内容并将其存入数据库。使用者提交检索条件(例如关键字),搜索引擎返回满足查询条件的数据列表。从理论上讲,调价是很重要的。简而言之,我们将条件设置为一个或多个由空格分割的单词,而检索条件代表的是同时包含这些单词的数据。
实际上,搜索引擎都有分词机制。(比如市场上的jieba分词)假设“小明的博客”作为搜索关键词,搜索引擎会把它分解成三个单词["小明"、"的"、"blog"],而"的"作为无意义的停顿词(stopword)被过滤掉。对分词和单词权重评估算法(TF-IDF算法,textrank算法等)进行分析。
通过这种方式,建立搜索引擎变得简单:1.建立数据库,2.建立一个数据结构,根据关键词查找包含单词的页面。
数据库的创建
一般都通过称为spider的特殊程序实现(当然,专业领域搜索引擎,比如学术会议的论文检索系统)可以直接从数据库构建数据。
简单地说,爬行器以页面开始(例如新浪的主页),通过http协议进行通信获取页面的所有内容。记下该页的网址和内容。然后,分析页面中的链接,并从这些链接中分别获取这些链接到页面的内容。做完记录后,再分析网页的链接…重复这一过程,就能看到整个互联网的所有网页。
当然,这是个理想状况。要求整个网络是强行连接的,所有页面上的机器人协议都支持爬行器爬升页面。为简单起见,我们依旧假定网络是一个强连通图,没有考虑到机器人协议。看一看。可以将数据库想像为大型键值结构,键值是页面的网址,值就是页面的内容。
数据结构的创建方法
另一种方法叫做倒排索引,实现了索引的数据结构。从理论上讲,倒排索引也是一组键值结构。keywords是关键字,值是一组页码(假设数据库每一页都有唯一数字),表明该页面含有该关键字。
根据上述分析,我们可以简单地解释搜索引擎的核心行为:搜索引擎获取“小明博客”的查询标准,把它分成两个字:“小明”和“博客”。{1、3、6、8、11、15},从倒排索引中分别找到与“小明”对应的集合;相应的blog集为{1、6、10、11、12、17、20,22},两个集合的交叉导致{1,6,11}最终,从数据库中查找与1、6、11对应的页面,并向用户返回它们。
对搜索引擎的核心挑战
上面介绍了一个非常简单的搜索引擎工作框架。虽然现代搜索引擎的具体原理要复杂得多,但其本质与这个简单的模型并无区别。实际上,谷歌在上述两个方面都不如其前辈。其最大的成功之处在于第三个,也是最难解决的问题:查询结果如何排序。
网页的数量是如此庞大,因此搜索结果条目的数量也是巨大的。举例来说,“小明博客"搜索返回的结果超过200万个。在如此众多的结果中,用户无法找到有用的信息,因此一个好的搜索引擎必须想办法使其具有高质量。
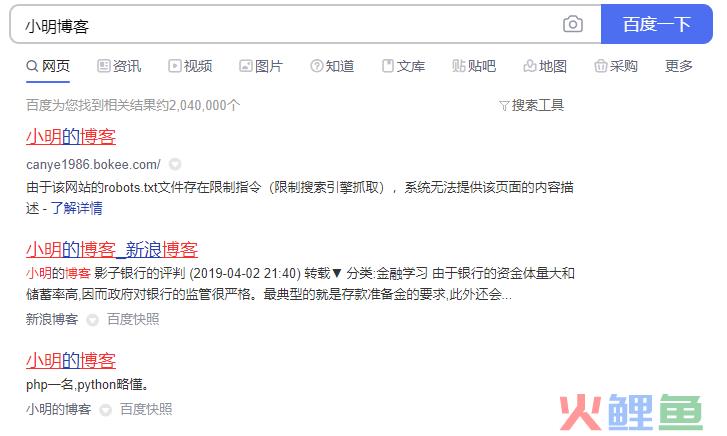
网页位于正面。实际上,直觉上,我们也可以感觉到,在使用搜索引擎的时候,我们并不太在意页面是否满了(这是上百万的结果,区别是什么?实际上,搜索引擎都是第一位的,实际上不会返回所有的结果),同时也很关心上一、二页的质量是否高,是否能满足我们的实际需求。
所以,根据搜索结果的重要性合理地排列搜索结果将成为搜索引擎最大的核心,也是谷歌最终成功的切入点。
早先搜索引擎实践
没有评价。
这种说法似乎有些荒谬,但实际上,很多早期的搜索引擎(甚至现在很多专业领域的搜索引擎)根本没有评估结果的重要性,而是直接按照自然顺序(比如时间顺序或者以数字顺序)返回结果。尽管结果集相对较小,这样做是有意义的,但一旦结果集变大,用户就会不断抱怨。你可以从数以千计的质量参差不齐的网页中找到你需要的内容,完全是一场灾难,这注定了这种方式对现代通用搜索引擎来说是不可能的。
根据搜索项评估
随后,一些搜索引擎引入了基于搜索关键字评估搜索结构重要性的方法。实际上,像tf-idf算法这样的方法依旧被用于现代搜索引擎,但是它们不再是评估质量的唯一指标。对tf-idf进行完整的描述相当繁琐。下面,用一个更简单的抽象模型来描述这种方法。
根据搜索结果进行评估的想法很简单:搜索项目的匹配程度越高,网页的重要性就越高。"配对"是要定义的具体度量。其中一个最直接的方法就是,关键字匹配的页面越多级别越高。还有一个搜索“小明博客”的例子:假设首页有“小明”5次,“博客”10次;“张洋”第二页出现两次,“博客”出现八次。所以A页面的匹配度是5+10=15,B页是2+8=10。所以,人们认为网页的重要性比网页更重要。很多朋友可能意识到这一点并不合理:内容较长的网页比内容短的网页更有可能拥有更多关键字。所以,我们克服上述不合理性的方法是将关键字出现的次数除以页面上的总字数,即使用关键字比例作为匹配度来修改算法。
有些早期的搜索引擎也是根据相似的算法评估网页的重要性。这个估计算法看起来合理而且易于实现,但它很容易被称为spammer的攻击。
TermSpam
实际上,从搜索引擎诞生之日起,termspam和搜索引擎就没有停止与作弊的斗争。spammer是一群试图通过搜索引擎算法中的漏洞(通常是广告页或垃圾页)提高目标页的重要性,从而使目标页在搜索结果中处于领先地位的人。
假设谷歌只使用关键词比例来评估页面的重要性,我希望我的博客在搜索结果中排名更高(最好是第一)。那我就可以这么做了:给页面添加隐藏html元素(如一个div),然后重复10,000次的内容“小明”。通过这种方式,当搜索引擎计算“小明”在搜索结果时,我的博客关键词占了很大比例,从而达到了排名靠前的效果。另外,我还可以干扰其他关键词的搜索结果。比如,我知道欧洲杯很受欢迎,我已经在blog中添加了10,000个“欧洲杯”。如果用户搜索欧洲杯,我的博客就会出现在搜索结果的最上面。这样的行为叫做“TermSpam"。
而早期搜索引擎被这种欺骗方式所困扰,基于关键词的算法本身也不太合理,往往出现许多质量不佳的结果,极大地降低了用户体验。就是在这样的背景下,谷歌推出PageRank算法并获得专利保护。这一举动在当时保护了相对弱势的谷歌,也让谷歌成为了一个领先搜索引擎。
PageRank算法
正如上面提到的,PageRank用来评估网页的重要性,这是排序搜索结果的重要依据。实际上,为了防止TermSpam,每个搜索引擎都有特定的排名算法都是保密的,PageRank算法也不一样。最简单的基于页面链接属性的PageRank算法很简单,但是可以揭示PageRank算法。实际上,链接属性是计算主流搜索引擎流量的一个重要指标。
简易PageRank计算
PageRank算法是一种网页排序算法,它有两个基本思想:
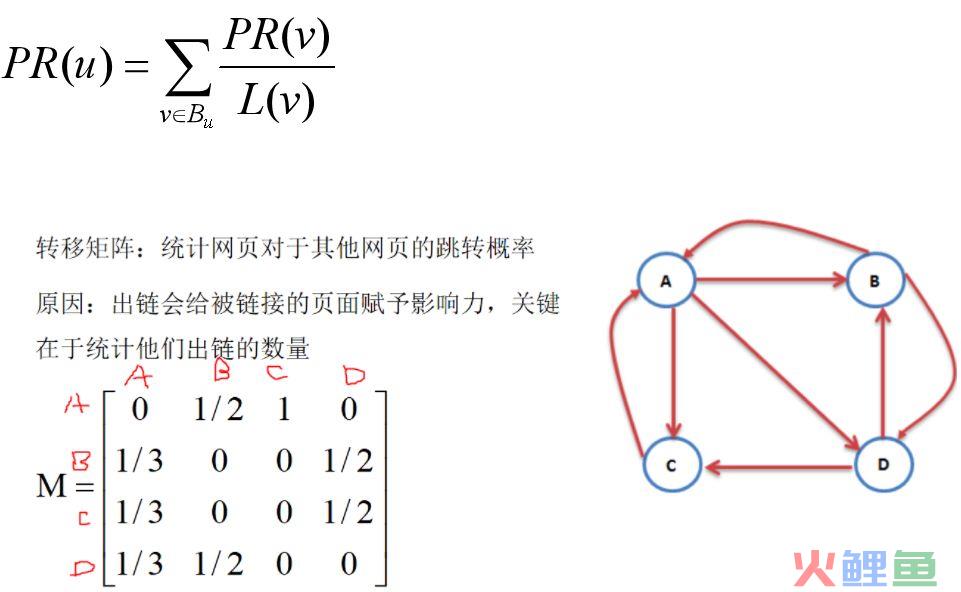
链路数量。有越多的网页链接,说明该网页越重要。链路质量。页面的权值越大的网页链接越多,也会显示出该网页越重要。
在此基础上,网页的PageRank算法的值公式
S(Vi)=∑j(In)(Vi)(|Out(Vj)|/1*S(Vj))
In(Vi)是Vi的入链集合,同理,Out(Vj)为Vj的出链集合,|Out(Vj)|表示出链数。由于每页出链对每一个出链的平均分值,|Out(Vj)|/1*S(Vj)对vj贡献给vi的分数。把vi所有加入到他身上的分数加起来,就是vi本身的分数。
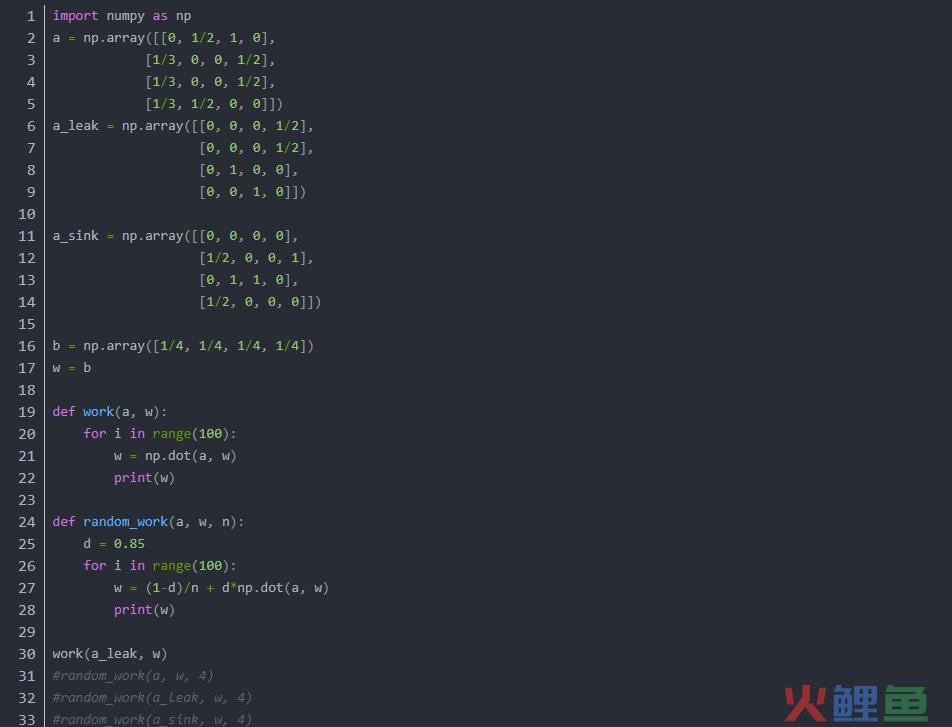
用这种方法计算每页的分数是有个问题的,当然,每页的得分都和它的链接网页的分数有关,那么它的链接网页的分数应该如何决定呢?要解决这个问题,在算法开始时,首先将所有网页的得分初始化为1,然后通过多次迭代使每个网页的分数收敛。收敛性得分即为网页的最终得分。如果无法收敛,也可以通过设置最大迭代次数来控制计算,当停止时的分数就是网页的得分。
Dead Ends
上述PageRank算法假定该网络是强连接的,但实际上网络并没有强连接(甚至没有连接)。来看一下PageRank算法是如何处理“死胡同”的。
Dead Ends是没有外链的节点,已经死掉了末端。以上方法能够收敛到非零值的原因很大程度上取决于传递矩阵的性质:每列之和为1,第四列m是0,没有死胡同的在结尾处,向量v的项目的总和在每一次迭代之后都保持为1。如果是这样,迭代结果最终会回到0(为了解释为什么会这样,需要一些矩阵理论的知识,这很无聊,这里省略)。
对死胡同的处理方法为:迭代移除中的末端节点和与末端节点相关的边,直到没有死胡同。计算剩余部分的rank,然后按反序推回末端的rank,并将死胡同移除结束。
就拿上面的数字来说。先求边与D和D有关。拿到D之后,C就是死胡同。除去C,最后只剩下A和B。这时,计算a和b的PageRank算法为1/2是很容易的。那就得倒推死胡同的rank,最终删除的是C,我们可以看到C前的节点是A和B,A和B的度数是3和2,因此C的rank是1/2*1/3+1/2*1/2=5/12;最后,d的等级是:1/2*1/3+5/12*1=7/12。因此,最后一页(1/2,1/2,5/12,7/12)。
SpiderTraps和平滑
如果把真实的网络组织为一个转移矩阵,那么它就是一个非常稀疏的矩阵。根据矩阵论的知识,我们可以推断极稀疏转移矩阵的迭代乘方法将导致矢量V是不平滑的,即有些结点的秩较大,多数结点的秩值接近0。一种名为蜘蛛陷阱的节点的出现加剧了这种不一致。
话题敏感的PageRank
实际上,上面的讨论回避了这样一个事实:“网页的重要性”并没有标准的答案,甚至在不同的使用者中也有很大的差别。比如,在搜索“苹果”的时候,数字发烧友也许想要了解iphone的信息,果农可能想了解苹果的价格趋势和种植技术,孩子们也许在寻找苹果的棒状图。理论上,每个用户都应该维护一组数据。但是这种方法显然不适合大量用户使用。所以,搜索引擎经常选择一种称为主题敏感的折中方案。
PageRank的方法是预先定义主题类别,比如体育、娱乐、技术等等。对每一个主题分别保持向量,然后找到关联用户主题倾向的方式,并根据用户的主题进行分类。向排名结果倾斜。
按照以下步骤对主题敏感页进行排序:
1.确定主题分类
通常,你可以是开放式的第一级目录(dmoz)被称为主题。现在,dmoz的主题包括:艺术,商业,电脑,游戏,健康,家庭,儿童,新闻,娱乐,参考,地区,科学,科技,购物,社交,运动。
2.网页的主题定位
这个步骤需要对每个页进行分类,使之为最合适的类别。具体的分类有很多算法。举例来说,tf-idf可以用于基于语素的分类,也可以在聚类之后进行手工分类,而且特定的分类不会被扩展。这个步骤的最终结果是,每个页被分成一个主题。

3.识别用户主题倾向
当用户提交搜索时,识别出主题倾向,以便选择合适的排名矢量。主要有两种方法。一个是列出所有的主题,让用户选择感兴趣的计划。这个方法经常被一些社交问答网站使用。另外一种方法是以某种方式(比如cookies跟踪)跟踪用户的行为,并通过数据分析来判断用户的倾向。
垃圾信息链接
回过头看这个例子,如果我想让我的博客在搜索“张洋博客”时排名靠前,用PageRank算法中的TermSpam是不可能的。不过,因为我知道PageRank主要依靠内部链接的数量来计算页面权重,所以我可以考虑建立许多链接到我的博客主页的裸站,这样就可以改善博客的主页了?很遗憾,这个方法行不通。在PageRank算法中,页面平均分配权重给链接站点,因此除了内部链接数量外,上游页面的权重也非常重要。不过,我的裸站本身就是没有重量的,因此它们的内链不能提高博客主页的排名,这仅仅是自娱。所以,垃圾网页排名的关键就是找出如何添加一些高权重网页内部链。来看看垃圾信息链接是怎么做的。
一开始,页面被分成几类:
1.目标页
目标页就是垃圾信息发送者希望改善排名的网页。
2.支持页
受支持页是垃圾信息发送者完全能够控制的页,如垃圾信息发送者自己创建的站点中的网页。以上提到的是我所说的空书架页。
3.无障碍页
垃圾信息发送者不能完全控制可访问页,但是垃圾信息发送者可以在界面上发布链接,比如天涯社区、新浪博客以及用户可以发布的其他社区或博客网站。
4.不可访问页
那些是垃圾信息发送者根本不能发布链接的网站,比如政府网站、百度主页等等。
身为垃圾信息发送者,可以使用的资源是支持页和可访问页。正如上面所提到的,完全不可能通过支持页来发送垃圾信息,所以首先要做的就是寻找一些更高级别的可访问网页,在博客首页添加一个链接。比如,可以去天涯,茅埔等等回帖:“主持人的帖子很好!要点:seo技术站点https://xxx.com。在大社区,我想没有人会看到这样的帖子。有人在搞垃圾信息。通过将每个支持页与目标页互锁,在支持页中扩大排名,每个支持页只有一个链接。
连结反欺骗的垃圾信息
搜索引擎的反作弊工程师们需要找到一种检测垃圾信息发送者链接垃圾信息的方法。通常,有两种检测链接垃圾信息的方法。
网路拓扑分析
一种方法是通过分析网页的图形拓扑结构,发现可能存在的垃圾信息场。但是,随着网络规模的不断扩大,这种方法变得十分困难,因为对图的特殊结构搜索是一种时间复杂的算法,不可能仅仅依靠它来对付作弊。
trustrank
一个更有可能的反欺骗的方法称为信任等级法。实际上,trustrank的数学本质上就是主题敏感级别,除了“受信任的网页”虚拟主题之外。所谓“受信任”的网页是上面提到的不可访问的网页,或者不可能是垃圾信息的网页。比如,政府网站、新浪、网易门户等。一般而言,一个“受信任的网页”集合是通过人工或者其他方法选择形成一个主题,然后通过上面的主题敏感性算法对这个主题进行排名,结果被称为信任等级(trustrank)。
trustrank的思维非常直觉:如果一个页面的正常排名远远高于受信任页面的主题,那么这个页面很可能是垃圾信息。定义页的垃圾信息数量是:(p–t)/p,如果页面是正常的p,那么信任级别是t。越多的垃圾信息,这个网页就会越容易变成垃圾信息网页。
总结
总结了一些资料,简要介绍了PageRank的背景、作用、算法、变种、Spam和防篡改等内容。为强调重点,简化了搜索引擎的模型,当然在实际中并不是那么简单,真正的算法一定很复杂。但是,现在几乎所有搜索引擎的页面权重计算方法都是基于PageRank及其变体。由于我没有做过与搜索引擎相关的开发,所以本文的内容主要是基于对现有文献的客观总结。